
Sportvorhersagen
Ladevorgang...
Ladevorgang...
Wer sich ernsthaft mit Sportwetten beschäftigt, kommt an einem Thema nicht vorbei: Statistik. Denn hinter den scheinbar magischen Vorhersagen moderner KI-Systeme verbirgt sich nichts anderes als die systematische Auswertung von Zahlen, Daten und Fakten. Die gute Nachricht für alle, die beim Wort Mathematik zusammenzucken: Man muss kein Statistik-Diplom besitzen, um die Grundprinzipien zu verstehen und davon zu profitieren. Allerdings sollte man zumindest wissen, wie die Maschinen ticken, denen man seine Wettentscheidungen anvertraut.
Die Bundesliga bietet für statistische Analysen einen nahezu perfekten Nährboden. Seit Jahrzehnten werden hier akribisch Daten gesammelt, von simplen Ergebnissen bis hin zu komplexen Tracking-Informationen, die jeden Ballkontakt erfassen. Diese Datenfülle ermöglicht es KI-Systemen, Muster zu erkennen, die dem menschlichen Auge verborgen bleiben. Doch wie bei jedem Werkzeug gilt auch hier: Wer versteht, wie es funktioniert, kann es besser einsetzen. Genau deshalb lohnt sich der Blick hinter die Kulissen der statistischen Analyse.
Viele Sportwetter verlassen sich auf ihr Bauchgefühl oder folgen blind den Tipps selbsternannter Experten. Das kann gelegentlich funktionieren, führt aber langfristig selten zum Erfolg. Der statistische Ansatz bietet eine Alternative, die auf Fakten statt auf Vermutungen basiert. Verlasse dich auf harte Fakten und historische Daten bei unseren AI Bundesliga Wett-Tipps. Dabei geht es nicht darum, die menschliche Intuition vollständig zu ersetzen, sondern sie durch objektive Daten zu ergänzen und zu verfeinern. Die Kombination beider Ansätze verspricht die besten Ergebnisse.
Die statistische Basis von KI-Wettprognosen
Bevor wir uns in die Tiefen der Wahrscheinlichkeitsrechnung stürzen, lohnt ein Blick auf das Fundament. KI-Systeme für Bundesliga-Prognosen arbeiten nicht mit Bauchgefühl oder Expertenwissen im klassischen Sinne. Stattdessen füttern Entwickler ihre Algorithmen mit historischen Daten, aus denen die Maschine lernt, zukünftige Ereignisse einzuschätzen. Dieser Lernprozess ist das Herzstück jeder modernen KI-Anwendung im Sportwettenbereich.
Die Bandbreite der verwendeten Datenpunkte ist dabei erstaunlich. Am Anfang stehen natürlich die offensichtlichen Informationen wie Spielergebnisse, Tore, Siege und Niederlagen. Ein Blick in die Tabelle verrät, welche Mannschaften erfolgreich sind und welche kämpfen müssen. Doch moderne Systeme gehen weit darüber hinaus. Sie erfassen Ballbesitzwerte, Passgenauigkeit, Zweikampfquoten, Laufleistungen und Sprintdistanzen. Besonders wertvoll sind dabei die sogenannten Expected Goals, kurz xG, die wir später noch genauer betrachten werden.
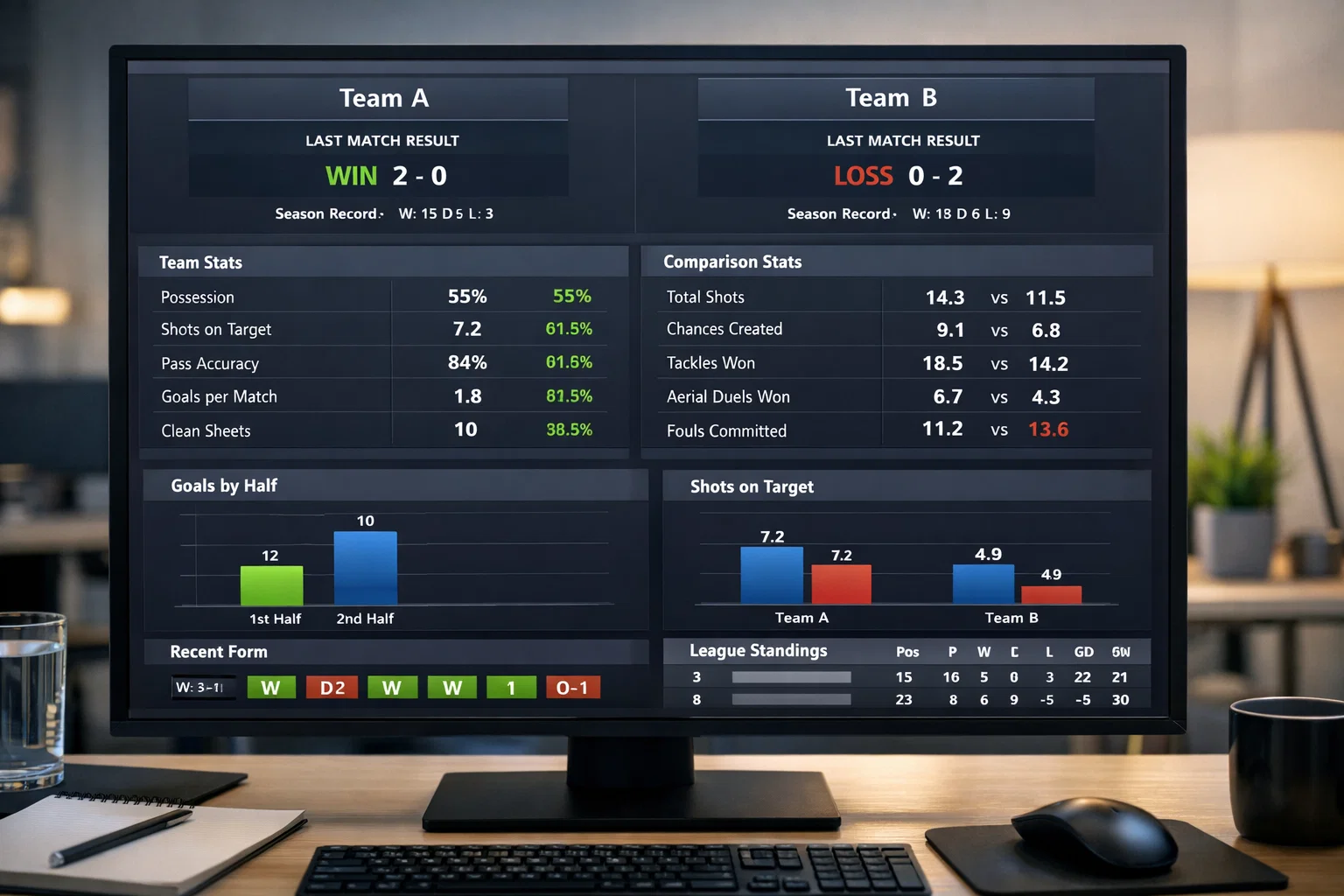
Die Datenquellen für solche Analysen sind vielfältig. Professionelle Anbieter wie Opta, Sportec Solutions oder StatsBomb erfassen jeden Spielzug in den großen europäischen Ligen. Ihre Datenbanken umfassen Millionen von Ereignissen, vom simplen Pass bis zum spektakulären Fallrückzieher. Diese Informationen werden in strukturierte Formate überführt, die Algorithmen verarbeiten können. Die Qualität dieser Eingabedaten bestimmt maßgeblich die Güte der späteren Vorhersagen.
Der Sprung von der deskriptiven zur prädiktiven Statistik ist dabei entscheidend. Deskriptive Statistik beschreibt, was passiert ist: Bayern München hat in der vergangenen Saison 88 Tore geschossen, der VfL Bochum nur 32. Das sind interessante Fakten, aber für zukünftige Wetten nur bedingt nützlich. Prädiktive Statistik versucht hingegen vorherzusagen, was passieren wird: Wie viele Tore wird Bayern im nächsten Spiel gegen Hoffenheim erzielen? Für Sportwetter ist diese Unterscheidung fundamental, denn nur prädiktive Modelle liefern verwertbare Informationen für zukünftige Wetten.
Nicht jede Statistik ist dabei gleich aussagekräftig. Ein häufiger Fehler besteht darin, irrelevante Zahlen überzubewerten. Dass ein Team seine letzten fünf Heimspiele gewonnen hat, klingt beeindruckend, sagt aber wenig aus, wenn die Gegner allesamt aus dem Tabellenkeller kamen. KI-Systeme sind darauf trainiert, solche Zusammenhänge zu erkennen und entsprechend zu gewichten. Sie unterscheiden zwischen Korrelation und Kausalität, zwischen aussagekräftigen Mustern und statistischem Rauschen. Diese Fähigkeit zur Mustererkennung macht den eigentlichen Wert der künstlichen Intelligenz aus.
Das Prinzip Garbage In, Garbage Out gilt auch für die ausgefeiltesten Algorithmen. Wenn die Eingabedaten fehlerhaft oder unvollständig sind, können auch die besten Modelle keine zuverlässigen Vorhersagen liefern. Seriöse KI-Anbieter wie BETSiE greifen daher auf professionelle Datenquellen zurück, die von spezialisierten Unternehmen bereitgestellt werden. Diese Firmen beschäftigen Heerscharen von Analysten, die jeden Spielzug katalogisieren und in maschinenlesbare Formate überführen. Die Investition in hochwertige Daten zahlt sich durch genauere Prognosen aus.
Ein weiterer wichtiger Aspekt ist die zeitliche Dimension der Daten. Informationen aus der vergangenen Saison sind weniger aussagekräftig als aktuelle Werte. Teams verändern sich durch Transfers, Trainerwechsel und taktische Anpassungen. Ein Modell, das nur auf historischen Daten basiert, ohne aktuelle Entwicklungen zu berücksichtigen, wird zwangsläufig Fehler machen. Die besten KI-Systeme aktualisieren ihre Datenbasis kontinuierlich und gewichten neuere Informationen stärker als ältere.
Wichtige statistische Konzepte für Wetter
Um KI-Prognosen richtig einordnen zu können, sollte man einige grundlegende statistische Konzepte verstehen. Das beginnt bei der simplen Umrechnung von Wahrscheinlichkeiten in Quoten und umgekehrt. Eine Quote von 2.00 entspricht einer impliziten Wahrscheinlichkeit von 50 Prozent. Unsere Berechnungen liefern dir zu jedem Spiel eine präzise Wahrscheinlichkeit für den Ausgang. Die Formel dafür lautet: Wahrscheinlichkeit gleich eins geteilt durch Quote. Bei einer Quote von 2.50 ergibt das 40 Prozent, bei 1.50 sind es etwa 67 Prozent.
Diese Umrechnung ist das Handwerkszeug jedes erfolgreichen Sportwetters. Wer nicht versteht, welche Wahrscheinlichkeit hinter einer Quote steckt, kann keine fundierten Entscheidungen treffen. Angenommen, ein Buchmacher bietet für den Heimsieg von Borussia Dortmund eine Quote von 1.80 an. Das entspricht einer impliziten Wahrscheinlichkeit von etwa 56 Prozent. Wenn die eigene Analyse eine höhere Wahrscheinlichkeit ergibt, etwa 62 Prozent, dann liegt möglicherweise eine Value Bet vor, also eine Wette mit positivem Erwartungswert.
Buchmacher kalkulieren ihre Quoten nicht nur auf Basis von Wahrscheinlichkeiten, sondern bauen eine Gewinnmarge ein. Diese sogenannte Überrundung oder Vigorish sorgt dafür, dass die Summe der impliziten Wahrscheinlichkeiten aller Ausgänge mehr als 100 Prozent beträgt. Bei einem typischen Bundesliga-Spiel mit drei möglichen Ausgängen liegt die Überrundung oft zwischen drei und acht Prozent. Ein einfaches Rechenbeispiel verdeutlicht das: Wenn der Heimsieg mit 2.00 quotiert ist (50 Prozent), das Unentschieden mit 3.50 (29 Prozent) und der Auswärtssieg mit 3.20 (31 Prozent), ergibt die Summe 110 Prozent. Die überschüssigen 10 Prozent sind die Marge des Buchmachers.

KI-Systeme kalkulieren ihre eigenen Wahrscheinlichkeiten und vergleichen diese mit den Buchmacher-Quoten, um Value Bets zu identifizieren. Der Prozess läuft dabei automatisiert ab: Das System berechnet für jedes Spiel die Wahrscheinlichkeiten aller Ausgänge, rechnet diese in faire Quoten um und vergleicht sie mit den angebotenen Quoten. Wo die Buchmacher-Quote höher ist als die faire Quote, liegt theoretisch Value vor. Allerdings ist dies nur ein theoretischer Vorteil, der sich erst über viele Wetten hinweg realisiert.
Die Standardabweichung ist ein weiteres wichtiges Konzept, das viele Sportwetter unterschätzen. Sie misst, wie stark einzelne Werte vom Durchschnitt abweichen. Im Fußball-Kontext kann man damit einschätzen, wie berechenbar ein Team spielt. Eine Mannschaft mit niedriger Standardabweichung bei den erzielten Toren liefert konstante Leistungen, während eine hohe Standardabweichung auf Unberechenbarkeit hindeutet. Für Über/Unter-Wetten ist diese Information Gold wert.
Stellen Sie sich zwei Teams vor, die beide im Schnitt 1,5 Tore pro Spiel erzielen. Team A erzielt regelmäßig ein bis zwei Tore, während Team B zwischen null und vier Treffern schwankt. Die Durchschnittswerte sind identisch, aber die Verteilungen unterscheiden sich fundamental. Bei Team A wäre eine Wette auf Unter 2,5 Tore relativ sicher, bei Team B deutlich riskanter. Die Standardabweichung quantifiziert diesen Unterschied und ermöglicht differenziertere Entscheidungen.
Die Varianz, das Quadrat der Standardabweichung, spielt bei der Bewertung von Wettstrategien eine zentrale Rolle. Eine Strategie mit hoher Varianz kann kurzfristig spektakuläre Gewinne oder Verluste produzieren, während eine Strategie mit niedriger Varianz stabilere, wenn auch möglicherweise bescheidenere Ergebnisse liefert. Professionelle Wetter achten nicht nur auf die erwartete Rendite, sondern auch auf das Risikoprofil ihrer Strategien. Das sogenannte Kelly-Kriterium, eine mathematische Formel zur optimalen Einsatzberechnung, berücksichtigt beide Faktoren.
Ein oft übersehener Aspekt ist die Frage der Stichprobengröße. Ab wann sind Daten statistisch aussagekräftig? Diese Frage hat keine pauschale Antwort, aber einige Faustregeln helfen. Fünf Spiele reichen definitiv nicht aus, um verlässliche Muster zu erkennen. Bei 20 Spielen werden die Daten schon brauchbarer, aber erst ab etwa 30 bis 50 Beobachtungen kann man von einer halbwegs robusten Datenbasis sprechen. Das erklärt, warum KI-Prognosen zu Saisonbeginn weniger zuverlässig sind als im Frühjahr, wenn bereits genügend Spiele absolviert wurden.
Für Aufsteiger wie den HSV oder den 1. FC Köln, die 2025/26 in die Bundesliga zurückgekehrt sind, stellt die begrenzte Datenbasis in der obersten Spielklasse eine besondere Herausforderung dar. KI-Systeme müssen hier auf ältere Bundesliga-Daten oder Zweitliga-Statistiken zurückgreifen, die naturgemäß weniger aussagekräftig für das aktuelle Leistungsvermögen sind. Entsprechend vorsichtig sollte man Prognosen für solche Teams bewerten, zumindest in der ersten Saisonhälfte.
Die Poisson-Verteilung: Das Herzstück der Torvorhersage
Wenn es einen statistischen Ansatz gibt, der für Fußballwetten unverzichtbar ist, dann die Poisson-Verteilung. Diese mathematische Verteilung eignet sich hervorragend, um seltene Ereignisse in einem festgelegten Zeitraum zu modellieren, und Tore im Fußball sind genau das: relativ seltene Ereignisse innerhalb von 90 Minuten Spielzeit.
Der französische Mathematiker Siméon Denis Poisson entwickelte diese Verteilung im 19. Jahrhundert, ohne zu ahnen, dass sie eines Tages Sportwetter auf der ganzen Welt beschäftigen würde. Die Grundidee ist simpel: Wenn man den Durchschnittswert eines Ereignisses kennt, kann man berechnen, mit welcher Wahrscheinlichkeit verschiedene konkrete Werte eintreten. Erzielt ein Team im Schnitt 1,5 Tore pro Spiel, lässt sich daraus ableiten, wie wahrscheinlich null, eins, zwei oder mehr Tore sind.
Der Physiker Metin Tolan, der lange an der TU Dortmund forschte und später Präsident der Universität Göttingen wurde, hat die Anwendbarkeit der Poisson-Verteilung auf den Fußball ausführlich untersucht. Seine Analysen zeigen, dass sich die Torverteilungen in der Bundesliga erstaunlich gut durch diese mathematische Funktion beschreiben lassen. Tore fallen offenbar nach ähnlichen statistischen Gesetzmäßigkeiten wie radioaktive Zerfallsereignisse, ein Vergleich, der zunächst absurd klingt, aber mathematisch durchaus Sinn ergibt. In seinem Buch über die Physik des Fußballspiels demonstriert Tolan diese Zusammenhänge anschaulich und erklärt, warum Fußball statistisch betrachtet der ungerechteste Sport der Welt ist.
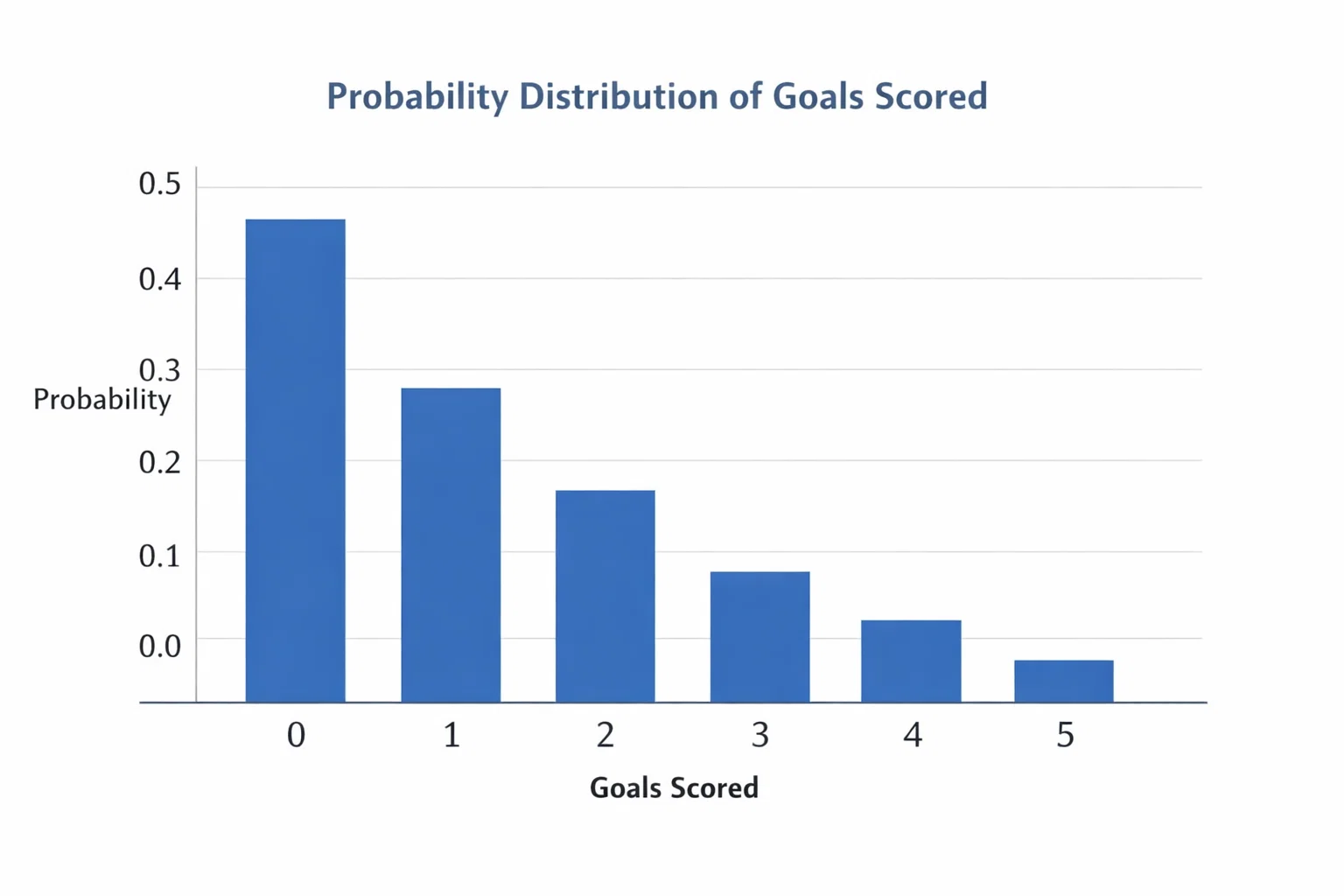
Die praktische Anwendung funktioniert folgendermaßen: Man ermittelt zunächst die durchschnittlichen Heim- und Auswärtstore beider Teams, basierend auf historischen Daten. Dabei kann man die Angriffsstärke des einen Teams mit der Defensivstärke des anderen kombinieren. Aus diesen Werten berechnet man dann die erwartete Toranzahl für jede Mannschaft. Mit der Poisson-Formel lassen sich anschließend die Wahrscheinlichkeiten für sämtliche Spielausgänge ermitteln.
Konkret sieht das so aus: Angenommen, die Heimmannschaft hat eine erwartete Toranzahl von 1,8 und die Gastmannschaft von 1,2. Die Poisson-Verteilung liefert dann Wahrscheinlichkeiten für jedes exakte Ergebnis. Die Wahrscheinlichkeit für ein 0:0 berechnet sich aus dem Produkt der Wahrscheinlichkeiten, dass beide Teams null Tore erzielen. Für ein 1:1 multipliziert man die Wahrscheinlichkeiten, dass beide Teams genau ein Tor erzielen. So lässt sich eine komplette Matrix aller möglichen Ergebnisse erstellen.
In der Bundesliga fallen im Durchschnitt etwa 2,6 bis 3,0 Tore pro Spiel, wobei Heimmannschaften historisch betrachtet einen leichten Vorteil genießen. Der sogenannte Heimvorteil manifestiert sich statistisch in einer höheren durchschnittlichen Torausbeute der Gastgeber. KI-Systeme berücksichtigen diesen Faktor automatisch, aber als informierter Wetter sollte man wissen, dass er existiert und wie stark er sich auswirkt. Interessanterweise hat der Heimvorteil während der Corona-Pandemie mit Geisterspielen deutlich abgenommen, was die Bedeutung der Fans für die Spielerleistung unterstreicht.
Eine Stärke der Poisson-Verteilung liegt in ihrer Vielseitigkeit. Sie eignet sich nicht nur für klassische Siegwetten, sondern auch hervorragend für Über/Unter-Märkte. Wenn die Poisson-Berechnung eine Gesamttorerwartung von 2,4 Toren ergibt, kann man daraus die Wahrscheinlichkeit für verschiedene Schwellenwerte ableiten: Wie wahrscheinlich sind mehr als 2,5 Tore? Weniger als 3,5? Auch für Handicap-Wetten und exakte Ergebnisse liefert die Verteilung wertvolle Anhaltspunkte.
Die mathematische Formel selbst ist dabei gar nicht so kompliziert. Sie verwendet nur den Erwartungswert (die durchschnittliche Toranzahl) und die Eulersche Zahl als Konstante. Moderne Tabellenkalkulationsprogramme haben die Poisson-Funktion standardmäßig eingebaut, sodass auch Laien eigene Berechnungen anstellen können. Wer sich die Mühe macht, ein eigenes Modell zu erstellen, gewinnt tieferes Verständnis für die Funktionsweise von KI-Prognosen.
Allerdings hat das Modell auch seine Grenzen. Die Poisson-Verteilung unterstellt, dass Tore unabhängig voneinander fallen, was in der Realität nicht immer stimmt. Wenn eine Mannschaft früh in Führung geht, verändert sich die Spielcharakteristik. Der Führende zieht sich möglicherweise zurück, während der Gegner offensiver agiert. Diese dynamischen Effekte erfasst das reine Poisson-Modell nicht. Fortgeschrittene KI-Systeme versuchen daher, diese Abhängigkeiten durch komplexere Modelle abzubilden, etwa durch die Berücksichtigung von Spielständen zu verschiedenen Zeitpunkten.
Ein weiterer Kritikpunkt betrifft die Annahme konstanter Wahrscheinlichkeiten über die Spielzeit. In Wirklichkeit steigt die Torwahrscheinlichkeit gegen Spielende oft an, wenn müde Defensivspieler Fehler machen oder Teams auf einen Ausgleich drängen. Statistiken zeigen, dass in der Schlussphase überproportional viele Tore fallen. Auch hier arbeiten Entwickler an verfeinerten Modellen, die solche zeitabhängigen Effekte berücksichtigen.
Korrelation vs. Kausalität: Häufige Fehler vermeiden
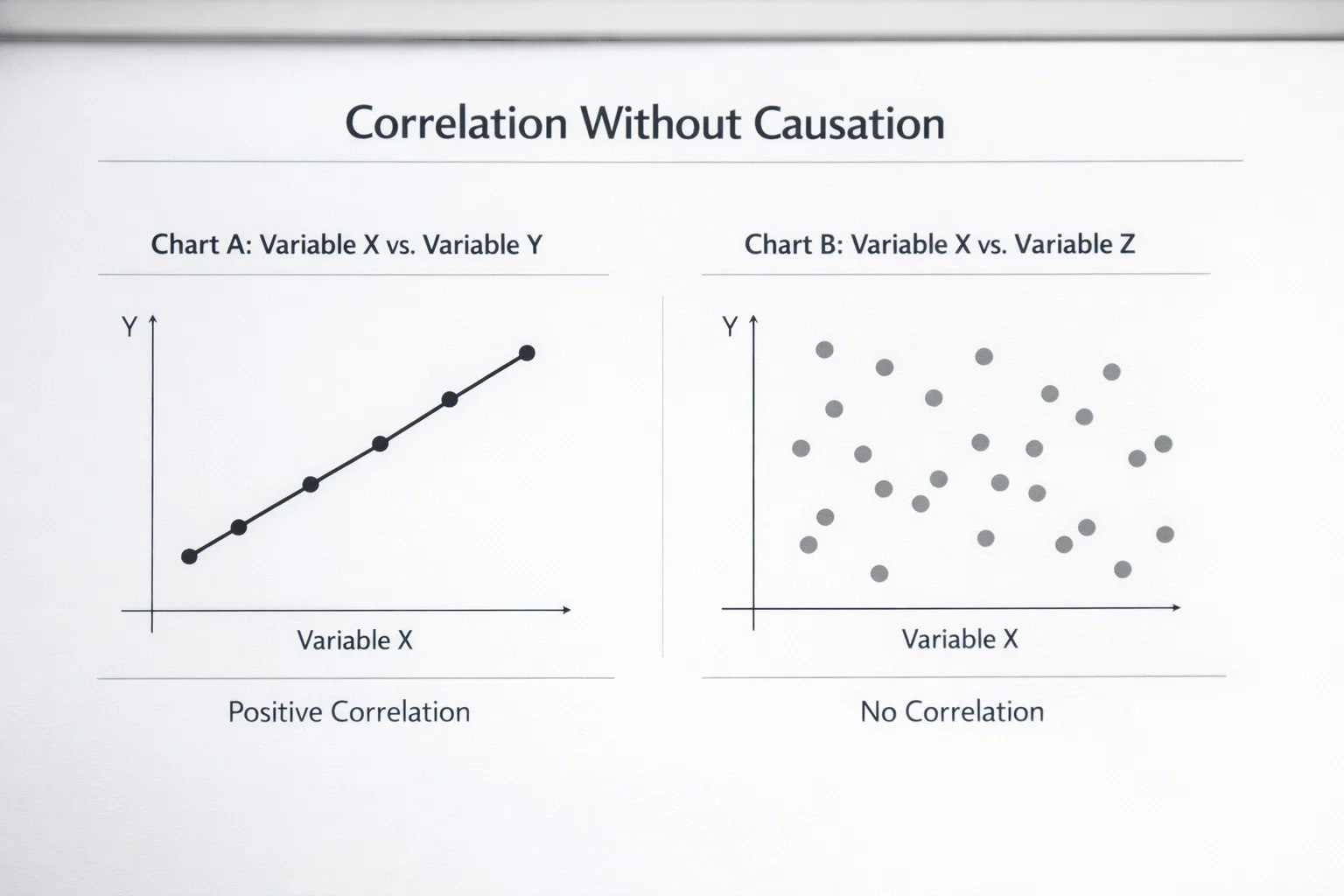
Ein klassischer Stolperstein bei der statistischen Analyse ist die Verwechslung von Korrelation und Kausalität. Nur weil zwei Ereignisse gemeinsam auftreten, bedeutet das nicht, dass eines das andere verursacht. Dieser Trugschluss ist im Fußball besonders verbreitet und führt zu falschen Schlussfolgerungen. Selbst erfahrene Analysten tappen gelegentlich in diese Falle.
Ein Beispiel: Wenn eine Mannschaft in roten Trikots statistisch häufiger gewinnt, liegt das nicht an der Farbe selbst. Vielmehr tragen mehrere erfolgreiche Teams wie Bayern München zufällig Rot. Die Korrelation zwischen Trikotfarbe und Erfolg ist spurios, also durch einen dritten Faktor verursacht, nämlich die Qualität der betreffenden Vereine. KI-Systeme können solche Scheinzusammenhänge erkennen und ausschließen, aber nur wenn sie richtig trainiert wurden.
Ein weiteres beliebtes Beispiel ist die sogenannte Hot-Hand-Illusion. Viele Wetter glauben, dass ein Spieler, der gerade mehrere Tore erzielt hat, mit höherer Wahrscheinlichkeit auch im nächsten Spiel treffen wird. Die statistische Evidenz dafür ist jedoch dünn. Die vergangenen Erfolge erhöhen nicht automatisch die Wahrscheinlichkeit zukünftiger Treffer, es sei denn, es gibt einen kausalen Mechanismus wie gesteigertes Selbstvertrauen oder verbesserte Fitness. Die Unterscheidung zwischen echten Mustern und Zufallsschwankungen erfordert sorgfältige Analyse.
Saisonale Verzerrungen stellen eine weitere Fehlerquelle dar. Die Bundesliga zeigt bestimmte Muster im Jahresverlauf, die nichts mit den Fähigkeiten einzelner Teams zu tun haben. Nach der Winterpause spielen viele Mannschaften beispielsweise anders als im Herbst, sei es aufgrund von Transferaktivitäten, veränderter Bodenverhältnisse oder unterschiedlicher Trainingsumfänge. Wer diese saisonalen Effekte ignoriert, riskiert systematische Fehleinschätzungen.
Auch die Reihenfolge der Spiele kann Muster erzeugen, die keine echte Aussagekraft haben. Wenn ein Team nach Europapokal-Spielen regelmäßig schwächer in der Liga spielt, liegt das möglicherweise an der Belastung durch die englischen Wochen, nicht an einem mysteriösen Zusammenhang zwischen Champions League und Bundesliga. Die kausale Erklärung ist wichtiger als die bloße Beobachtung des Zusammenhangs.
Besonders tückisch ist das Problem des Overfitting. Dabei passt ein Modell perfekt zu den historischen Daten, versagt aber bei der Vorhersage zukünftiger Ereignisse. Stellen Sie sich ein KI-System vor, das aus vergangenen Spielen gelernt hat, dass Team X immer verliert, wenn es regnet und gleichzeitig Vollmond ist. Dieses Muster mag in den Trainingsdaten zufällig aufgetreten sein, hat aber keinerlei prädiktive Kraft. Seriöse KI-Entwickler testen ihre Modelle daher an ungesehenen Daten, um Overfitting zu vermeiden.
Die Bundesliga bietet aufgrund ihrer Struktur einige spezifische Fallstricke. Die Dominanz des FC Bayern München verzerrt viele Statistiken. Wer den Rekordmeister in seine Berechnungen einbezieht, erhält andere Durchschnittswerte als jemand, der nur die übrigen 17 Teams betrachtet. KI-Systeme müssen entscheiden, wie sie mit solchen Ausreißern umgehen, und diese Entscheidung beeinflusst die Qualität der Prognosen erheblich.
Ein oft unterschätztes Problem ist die sogenannte Regression zum Mittelwert. Teams, die eine Phase außergewöhnlich guter oder schlechter Leistungen durchlaufen, tendieren dazu, zu ihrem langfristigen Leistungsniveau zurückzukehren. Wer nach einer beeindruckenden Siegesserie auf die Fortsetzung des Trends wettet, könnte böse überrascht werden. KI-Systeme erkennen solche Regressionstendenzen meist zuverlässiger als menschliche Beobachter, die von aktuellen Erfolgen geblendet werden.
Das Konzept der Regression zum Mittelwert ist für Sportwetter besonders relevant. Wenn ein Team in den ersten fünf Spielen zehn Tore erzielt hat, obwohl sein xG-Wert nur sechs erwartete Tore anzeigt, dann hat es wahrscheinlich über seinen Verhältnissen gelebt. Die Wahrscheinlichkeit ist hoch, dass die Torausbeute in den kommenden Spielen näher am xG-Wert liegen wird. Intelligente Wetter nutzen solche Diskrepanzen, um gegen überbewertete Teams zu setzen.
Praktische statistische Analyse eines Bundesliga-Spiels
Theorie ist gut, Praxis besser. Gehen wir Schritt für Schritt durch, wie eine fundierte statistische Analyse für ein konkretes Bundesliga-Spiel aussehen könnte. Als Beispiel dient eine fiktive Begegnung zwischen Borussia Dortmund und dem SC Freiburg. Die Methodik lässt sich aber auf jedes beliebige Spiel übertragen.
Zunächst sammeln wir die relevanten Basisdaten. Dortmund hat in den letzten 15 Heimspielen durchschnittlich 2,1 Tore erzielt und 1,0 Tore kassiert. Freiburg kommt auswärts auf einen Schnitt von 1,3 erzielten und 1,5 kassierten Treffern. Diese Werte bilden die Grundlage für eine einfache Poisson-Berechnung. Wichtig ist, dass wir nur relevante Daten verwenden, also Heimspiele für Dortmund und Auswärtsspiele für Freiburg.
Im nächsten Schritt verfeinern wir die Analyse durch Berücksichtigung der Stärkerelationen. Dortmund spielt gegen einen Gegner, der defensiv auswärts Schwächen zeigt. Freiburg trifft auf einen Gegner mit starker Offensive zuhause. Durch Gewichtung dieser Faktoren passen wir die erwarteten Torwerte an: Dortmund erwartete Tore 2,0, Freiburg erwartete Tore 1,1. Diese Anpassung berücksichtigt, dass nicht alle Gegner gleich stark sind.
Mit diesen Werten können wir nun verschiedene Wahrscheinlichkeiten berechnen. Die Poisson-Verteilung liefert uns die Chancen für jedes exakte Ergebnis. Das wahrscheinlichste Ergebnis ist 2:1 für Dortmund mit etwa 12 Prozent, gefolgt von 1:1 und 2:0 mit jeweils rund 10 Prozent. Aus der Summe aller Ergebnisse ergeben sich die Wahrscheinlichkeiten für die drei möglichen Ausgänge: Heimsieg etwa 58 Prozent, Unentschieden etwa 20 Prozent, Auswärtssieg etwa 22 Prozent.
Für Über/Unter-Wetten addieren wir die erwarteten Tore: 2,0 plus 1,1 ergibt 3,1 Tore. Die Poisson-Verteilung zeigt, dass die Wahrscheinlichkeit für mehr als 2,5 Tore bei etwa 64 Prozent liegt. Für mehr als 3,5 Tore sinkt sie auf rund 38 Prozent. Diese Zahlen können direkt mit den angebotenen Quoten verglichen werden. Wenn ein Buchmacher Über 2,5 Tore mit 1,50 quotiert, liegt die implizite Wahrscheinlichkeit bei 67 Prozent, was höher ist als unsere Einschätzung von 64 Prozent. Hier wäre also eher auf Unter zu wetten.
Der entscheidende Schritt folgt nun: der Vergleich mit den Buchmacher-Quoten. Angenommen, der Heimsieg wird mit 1,65 quotiert, was einer impliziten Wahrscheinlichkeit von 61 Prozent entspricht. Unsere Analyse ergab 58 Prozent. Die Differenz ist gering, und unter Berücksichtigung der Buchmacher-Marge ergibt sich kein klarer Value. Der Buchmacher sieht Dortmund sogar noch stärker als unser Modell.
Diese Analyse ist natürlich vereinfacht. Professionelle KI-Systeme wie BETSiE, das jedes Spiel etwa 20.000 Mal simuliert, berücksichtigen dutzende weitere Faktoren: Expected Goals aus den letzten Spielen, Spielerausfälle, taktische Aufstellungen, Erholungszeiten zwischen Spielen und vieles mehr. Der Grundgedanke bleibt jedoch derselbe: systematische Datenauswertung statt Bauchentscheidungen.
Ein wichtiger Aspekt fehlt noch: die Berücksichtigung von Unsicherheit. Unsere Punktschätzungen suggerieren eine Genauigkeit, die in der Realität nicht existiert. Seriöse Analysen liefern daher Konfidenzintervalle, also Bereiche, in denen der wahre Wert mit einer bestimmten Wahrscheinlichkeit liegt. Eine Siegwahrscheinlichkeit von 58 Prozent plus/minus 8 Prozent ist ehrlicher als eine scheinbar exakte Zahl.
Die praktische Umsetzung erfordert Disziplin und Konsequenz. Wer einmal eine Analyse durchführt und dann doch nach Bauchgefühl wettet, verschenkt den Vorteil der statistischen Methodik. Erfolgreiche Wetter halten sich an ihre Berechnungen, auch wenn das Ergebnis manchmal gegen die Intuition spricht. Langfristig zahlt sich dieser Ansatz aus, auch wenn einzelne Wetten verloren gehen.
Ressourcen für eigene statistische Recherche
Wer sich nicht allein auf KI-Systeme verlassen möchte, findet zahlreiche Ressourcen für eigene Analysen. Die offizielle Website der Deutschen Fußball Liga bietet grundlegende Statistiken zu allen Bundesliga-Spielen. Für tiefergehende Analysen existieren spezialisierte Plattformen, die auch fortgeschrittene Metriken wie Expected Goals bereitstellen. Viele dieser Angebote sind kostenlos nutzbar, während Premium-Funktionen kostenpflichtig sein können.
Tabellenkalkulationsprogramme sind unverzichtbare Werkzeuge für jeden, der eigene Modelle entwickeln möchte. Die Poisson-Funktion ist in gängigen Anwendungen standardmäßig enthalten. Mit etwas Einarbeitung lassen sich eigene Berechnungsmodelle erstellen, die als Ergänzung zu KI-Prognosen dienen können. Der Aufwand lohnt sich, denn das eigene Verständnis der Methodik verbessert auch die Interpretation fremder Analysen.
Für die mathematisch ambitionierteren Leser bieten Fachbücher zur Sportwetten-Statistik vertiefende Einblicke. Autoren wie Joseph Buchdahl haben umfangreiche Werke verfasst, die von Grundlagen bis zu fortgeschrittenen Methoden alles abdecken. Die Investition in solche Literatur zahlt sich für ernsthafte Sportwetter aus, denn Wissen ist der wichtigste Wettbewerbsvorteil in einem Markt, der zunehmend von Daten getrieben wird.
Online-Communities bieten die Möglichkeit zum Austausch mit Gleichgesinnten. In Foren und sozialen Medien diskutieren Wetter ihre Analysen und Strategien. Dabei lernt man oft mehr aus den Fehlern anderer als aus eigenen Experimenten. Allerdings ist Vorsicht geboten: Nicht jeder selbsternannte Experte im Internet verfügt über echte Kompetenz. Kritisches Hinterfragen ist immer angebracht.
Die Kombination verschiedener Quellen führt zu den besten Ergebnissen. KI-Prognosen liefern einen soliden Ausgangspunkt, eigene Analysen schaffen Verständnis für die Hintergründe, und der Austausch mit anderen Wettern hilft, blinde Flecken zu erkennen. Wer so vorgeht, hat die besten Chancen, langfristig erfolgreich zu wetten.
Letztlich bleibt Fußball trotz aller Statistik ein Spiel voller Überraschungen. Keine noch so ausgefeilte Analyse kann garantieren, was auf dem Platz passiert. Die Statistik verbessert unsere Einschätzungen, ersetzt aber nicht die grundlegende Unvorhersehbarkeit des Sports. Genau das macht ihn ja so faszinierend, und genau deshalb werden auch künftig Außenseiter gewinnen, Favoriten stolpern und Wettende überrascht werden.