
Sportvorhersagen
Ladevorgang...
Ladevorgang...
Wenn moderne KI-Systeme Bundesliga-Ergebnisse vorhersagen, steckt dahinter mehr als nur simple Statistik. Die leistungsfähigsten Algorithmen simulieren jedes Spiel tausende Male, um zu ihren Prognosen zu gelangen. Diese sogenannten Monte-Carlo-Simulationen gehören zum Standardrepertoire professioneller Sportwetten-Analyse und liefern deutlich robustere Vorhersagen als einfache Durchschnittswertberechnungen. Doch was genau passiert dabei, und wie lassen sich die Ergebnisse für eigene Wettentscheidungen nutzen?
Die Idee hinter der Simulation ist bestechend einfach: Anstatt ein Spiel nur einmal zu analysieren und ein wahrscheinlichstes Ergebnis zu ermitteln, lässt man es virtuell viele tausend Male austragen. Bei jedem Durchlauf werden zufällige Variationen eingebaut, die das Unvorhersehbare im Fußball abbilden. Am Ende zählt man aus, wie oft welches Ergebnis eingetreten ist, und erhält so eine Wahrscheinlichkeitsverteilung für alle möglichen Ausgänge. Diese Methodik hat sich in vielen Bereichen bewährt, von der Finanzwirtschaft bis zur Physik, und erobert nun auch die Welt der Sportwetten.
Im Vergleich zu anderen Prognosemethoden bieten Simulationen einen entscheidenden Vorteil: Sie berücksichtigen die inhärente Unsicherheit des Sports. Während deterministische Modelle ein einziges Ergebnis vorhersagen, zeigen Simulationen die gesamte Bandbreite möglicher Ausgänge. Das entspricht viel besser der Realität, in der auch scheinbar sichere Favoriten gelegentlich verlieren und Außenseiter überraschen können.
Was bedeutet simuliert bei KI-Prognosen?
Der Begriff Simulation kann irreführend sein. Es geht nicht darum, ein Computerspiel ablaufen zu lassen, bei dem virtuelle Fußballer über den Platz rennen. Stattdessen handelt es sich um mathematische Modelle, die den Ausgang eines Spiels auf Basis statistischer Annahmen berechnen, und zwar nicht einmal, sondern sehr oft.
Das Grundprinzip stammt aus der Monte-Carlo-Methode, die in den 1940er Jahren von Wissenschaftlern wie Stanislaw Ulam und John von Neumann entwickelt wurde. Ursprünglich diente sie der Berechnung physikalischer Prozesse im Rahmen des Manhattan-Projekts in Los Alamos, wurde aber schnell für andere Anwendungen entdeckt. Der Name leitet sich vom berühmten Casino in Monaco ab, was auf das zentrale Element des Verfahrens hinweist: den kontrollierten Einsatz von Zufall. Der Kollege Nicholas Metropolis schlug den Namen vor, inspiriert von der Spielleidenschaft von Ulams Onkel.
Im Kontext von Fußballprognosen funktioniert die Monte-Carlo-Simulation folgendermaßen: Das System kennt die statistischen Parameter beider Teams, etwa durchschnittliche Torerwartungen, Defensive-Stärken und historische Leistungswerte. Bei jedem Simulationsdurchlauf werden diese Basiswerte mit zufälligen Schwankungen versehen. Mal trifft der Stürmer seine Chancen besser als gewöhnlich, mal hat der Torhüter einen schwachen Tag. Diese Variationen bilden die natürliche Unberechenbarkeit des Sports ab.
Je mehr Simulationen durchgeführt werden, desto stabiler werden die Ergebnisse. Mit zehn Durchläufen erhält man noch stark schwankende Resultate. Bei hundert wird es besser, aber erst ab mehreren tausend Simulationen erreichen die Wahrscheinlichkeitsverteilungen eine zuverlässige Genauigkeit. Professionelle Systeme wie BETSiE, das von der Wettbasis betrieben wird, führen für jedes Bundesliga-Spiel etwa 20.000 Simulationen durch. Diese Zahl ist kein Zufall, sondern das Ergebnis von Erfahrungswerten: Sie liefert statistisch stabile Ergebnisse bei vertretbarem Rechenaufwand.
Der entscheidende Unterschied zu deterministischen Modellen liegt in der Berücksichtigung von Unsicherheit. Ein deterministisches Modell liefert für dieselben Eingabedaten immer dasselbe Ergebnis: Team A hat eine Siegwahrscheinlichkeit von 62 Prozent, fertig. Die Monte-Carlo-Simulation zeigt hingegen die gesamte Bandbreite möglicher Ausgänge und macht sichtbar, wie stark diese Prognose eigentlich schwanken kann. Vielleicht liegt die Siegwahrscheinlichkeit in 95 Prozent der Simulationen zwischen 55 und 69 Prozent, was deutlich mehr Information liefert als eine einzelne Punktschätzung.
Die technische Umsetzung erfordert Rechenleistung, aber keine Supercomputer. Moderne Laptops können tausende Simulationen pro Sekunde durchführen, sodass selbst komplexe Modelle in akzeptabler Zeit Ergebnisse liefern. Die eigentliche Herausforderung liegt nicht in der Rechenkapazität, sondern in der Qualität der zugrunde liegenden Modelle und Daten. Ein schlechtes Modell liefert auch nach Millionen Simulationen keine brauchbaren Ergebnisse.
Wie Supercomputer Bundesliga-Saisons simulieren
Die Simulation einzelner Spiele ist nur der Anfang. Richtig interessant wird es, wenn komplette Saisons virtuell durchgespielt werden. Dabei werden alle 306 Partien einer Bundesliga-Saison tausende Male simuliert, um Wahrscheinlichkeiten für Meisterschaften, Abstiege und Europapokal-Plätze zu berechnen.
Der von verschiedenen Medien zitierte Opta-Supercomputer ist eines der bekanntesten Beispiele für solche Saisonprognosen. Das System greift auf umfangreiche Datenbanken zurück, die jeden Spielzug der vergangenen Jahre erfassen. Daraus werden Stärkeprofile für alle Teams erstellt, die als Grundlage für die Simulationen dienen. Am Ende steht eine Tabelle mit Wahrscheinlichkeiten: Bayern München wird mit 76 Prozent Meister, Borussia Dortmund mit 12 Prozent, und so weiter. Diese Zahlen sind keine Vorhersagen im klassischen Sinne, sondern Auswertungen tausender virtueller Saisons.
Auch das KI-System BETSiE liefert regelmäßig solche Saisonprognosen für die Bundesliga. Zu Beginn der Spielzeit 2025/26 errechnete es für den FC Bayern München eine Meisterwahrscheinlichkeit, die deutlich über der der Konkurrenz lag. Der Rekordmeister wurde mit etwa 76 erwarteten Punkten an der Tabellenspitze gesehen, gefolgt von Bayer Leverkusen und RB Leipzig. Am anderen Ende der Tabelle prognostizierte die KI einen schweren Stand für die Aufsteiger HSV und 1. FC Köln, die beide mit dem Abstieg kämpfen sollten. Diese Prognosen haben sich im bisherigen Saisonverlauf als durchaus treffsicher erwiesen.
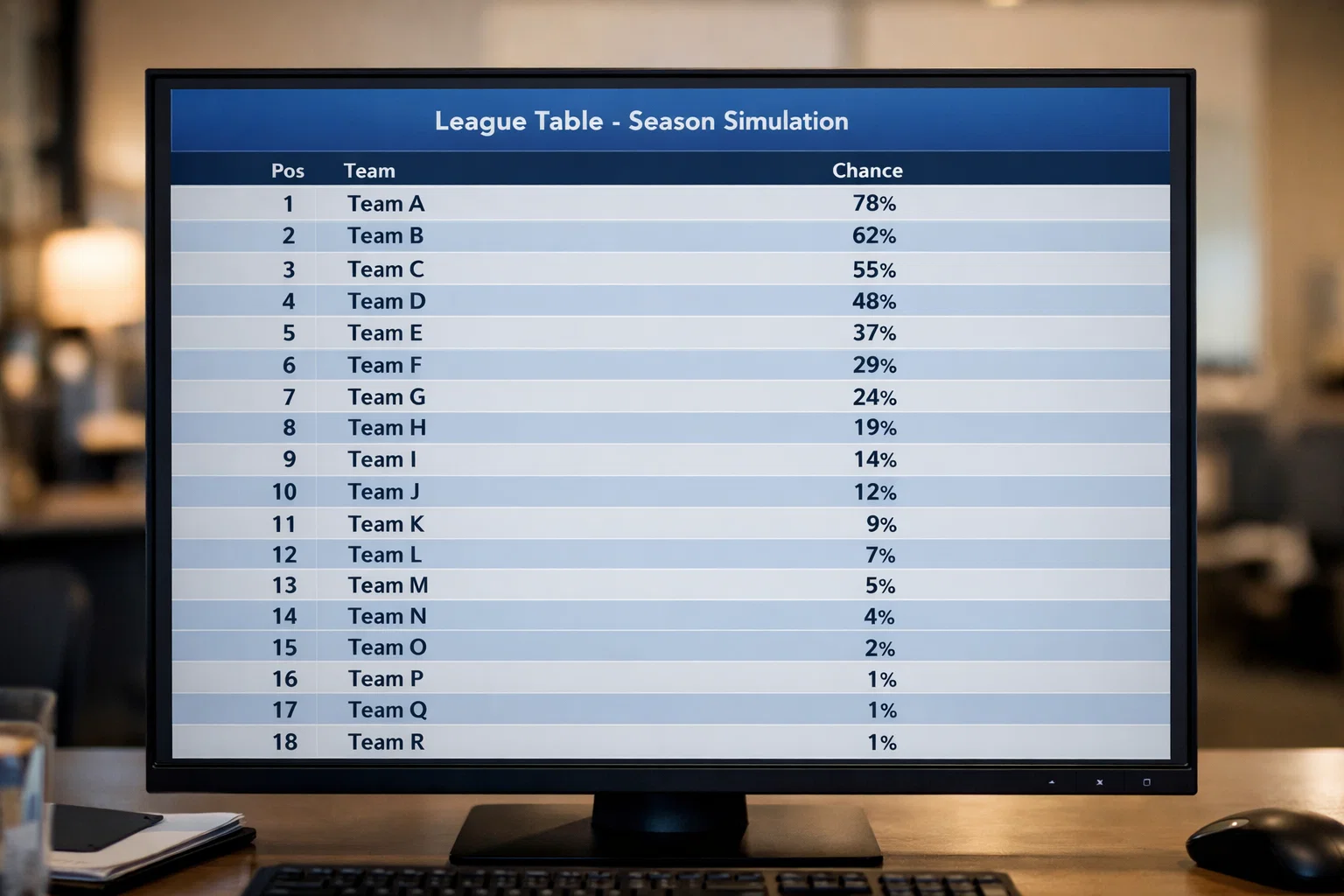
Bei jeder einzelnen Simulation variieren die Ausgänge der 306 Spiele. In einem Durchlauf gewinnt Dortmund das Spitzenspiel in München, im nächsten verliert es deutlich. Diese Variationen aggregieren sich über die Saison zu unterschiedlichen Tabellenständen. Manchmal wird Leipzig Meister, manchmal steigt Wolfsburg ab. Nach tausenden Durchläufen lässt sich zählen, wie oft jedes Team auf welchem Platz landete. Das Ergebnis ist eine Wahrscheinlichkeitsverteilung für alle Tabellenplätze jedes Teams.
Die Qualität solcher Saisonprognosen hängt stark von den zugrundeliegenden Annahmen ab. Transferaktivitäten, Verletzungen und Trainerwechsel lassen sich nicht vorhersagen und werden in den Modellen nicht berücksichtigt. Deshalb sind Saisonprognosen zu Beginn der Spielzeit mit Vorsicht zu genießen und müssen im Verlauf der Saison angepasst werden. Seriöse Anbieter aktualisieren ihre Simulationen daher nach jedem Spieltag, um neue Informationen einzuarbeiten.
Ein wichtiger Aspekt bei Saisonsimulationen ist die Interdependenz der Spiele. Wenn ein Team früh in der Saison wichtige Punkte verliert, beeinflusst das seinen weiteren Verlauf. Verletzte Spieler fehlen nicht nur in einem Spiel, sondern womöglich über Wochen. Das Selbstvertrauen nach einer Niederlagenserie kann schwinden. Diese kumulativen Effekte machen Saisonsimulationen komplexer als die Simulation von Einzelspielen. Die besten Modelle berücksichtigen solche Abhängigkeiten, auch wenn dies den Rechenaufwand erheblich steigert.
Die Transparenz der Methodik ist ein Qualitätsmerkmal seriöser Anbieter. BETSiE beispielsweise erklärt offen, dass ein Algorithmus mit unzähligen Komponenten jedes Spiel etwa 20.000 Mal analysiert. Dabei fließen nicht nur gewöhnliche Statistiken wie Tore und Tabellenstände ein, sondern auch historische Expected-Goals-Daten. Zugleich prognostiziert das System nicht nur einen einfachen Tipp, sondern Ausgangswahrscheinlichkeiten für verschiedene Wettmärkte und potenzielle xG-Daten für beide Teams.
Simulationsergebnisse richtig interpretieren
Die Ausgabe einer Monte-Carlo-Simulation ist keine einzelne Zahl, sondern eine Wahrscheinlichkeitsverteilung. Für Sportwetter, die an klare Tipps gewöhnt sind, kann das zunächst verwirrend wirken. Doch gerade in dieser Darstellung liegt der eigentliche Wert der Methode.
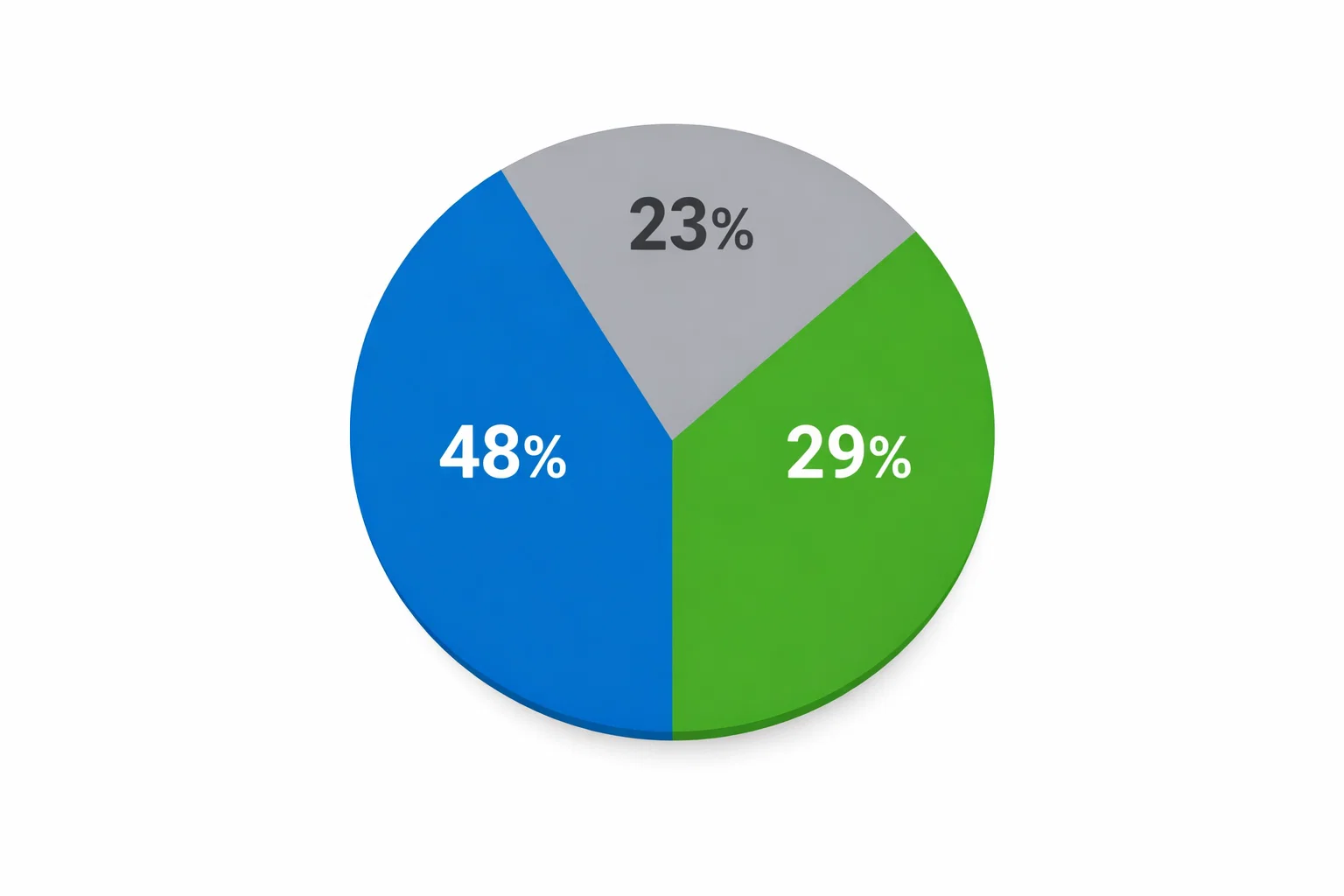
Betrachten wir ein konkretes Beispiel: Die Simulation für das Spiel Eintracht Frankfurt gegen Borussia Mönchengladbach liefert folgende Ergebnisse aus 10.000 Durchläufen. Heimsieg in 4.800 Fällen, Unentschieden in 2.300 Fällen, Auswärtssieg in 2.900 Fällen. Daraus ergeben sich Wahrscheinlichkeiten von 48 Prozent, 23 Prozent und 29 Prozent. Diese lassen sich mit den Buchmacher-Quoten vergleichen, um Value Bets zu identifizieren.
Konfidenzintervalle sind ein wichtiges Werkzeug zur Interpretation. Sie geben an, in welchem Bereich ein Wert mit einer bestimmten Wahrscheinlichkeit liegt. Wenn die simulierte Heimsiegwahrscheinlichkeit bei 48 Prozent plus/minus 5 Prozent liegt bei 95-prozentiger Konfidenz, bedeutet das: In 95 von 100 Fällen liegt der wahre Wert zwischen 43 und 53 Prozent. Diese Information ist wertvoller als eine scheinbar exakte Punktschätzung.
Die Form der Verteilung verrät ebenfalls viel über das Spiel. Eine schmale, spitze Verteilung deutet auf ein berechenbares Spiel hin, bei dem die Wahrscheinlichkeiten relativ sicher einzuschätzen sind. Eine breite, flache Verteilung signalisiert hohe Unsicherheit, etwa wenn beide Teams unberechenbar spielen oder die Datenlage dünn ist. Für Wetter kann diese Information entscheidend sein: Bei hoher Unsicherheit sind vielleicht Außenseiter-Wetten attraktiver, während bei geringer Unsicherheit der Favorit die sicherere Wahl darstellt.
Simulationen stoßen an ihre Grenzen, wenn es um Ereignisse geht, die statistisch nicht erfassbar sind. Ein Spieler, der plötzlich eingeschnappt ist, weil er auf der Bank sitzt. Ein Schiedsrichter, der einen umstrittenen Elfmeter gibt. Eine Rote Karte in der fünften Minute. Solche Ereignisse lassen sich zwar mit gewissen Wahrscheinlichkeiten in die Simulation einbauen, aber ihre konkreten Auswirkungen auf den Spielverlauf sind kaum modellierbar. Das Ergebnis ist eine inhärente Ungenauigkeit, die auch die beste Simulation nicht eliminieren kann.
Ein häufiger Fehler besteht darin, Simulationsergebnisse als Vorhersagen misszuverstehen. Wenn die Simulation eine Heimsiegwahrscheinlichkeit von 48 Prozent ergibt, heißt das nicht, dass das Heimteam wahrscheinlich gewinnt. Es bedeutet nur, dass es in 48 von 100 simulierten Spielen gewonnen hat, während es in 52 Fällen nicht gewonnen hat. Die Interpretation muss stets probabilistisch bleiben, was vielen Menschen schwer fällt. Unser Gehirn bevorzugt klare Aussagen, aber die Realität ist nuancierter.
Ein weiterer wichtiger Aspekt ist die Kalibrierung der Simulationen. Eine gut kalibrierte Simulation sollte über viele Spiele hinweg Wahrscheinlichkeiten liefern, die der tatsächlichen Eintrittsfrequenz entsprechen. Wenn ein System für 100 Spiele jeweils eine Heimsiegwahrscheinlichkeit von 60 Prozent prognostiziert, sollten etwa 60 dieser Spiele tatsächlich mit einem Heimsieg enden. Abweichungen davon deuten auf systematische Fehler im Modell hin.
Spielsimulationen für Einzelwetten nutzen
Die praktische Anwendung von Simulationen beginnt bei der Bewertung einzelner Wetten. Dabei geht es nicht nur um das Endergebnis, sondern um die gesamte Bandbreite der Wettmärkte, von Über/Unter bis zu Handicaps und exakten Ergebnissen.
Der Übergang von der Saisonsimulation zur Einzelspiel-Analyse ist dabei nahtlos. Dieselben Methoden, die komplette Spielzeiten durchrechnen, lassen sich auf einzelne Begegnungen anwenden. Der Unterschied liegt im Fokus: Während Saisonprognosen aggregierte Ergebnisse wie Tabellenplätze liefern, konzentrieren sich Einzelspiel-Simulationen auf die konkreten Ausgangswahrscheinlichkeiten der betreffenden Partie.
Für Über/Unter-Wetten sind Simulationen besonders wertvoll. Anstatt nur die durchschnittliche Torerwartung zu betrachten, zeigt die Simulation, wie oft bestimmte Gesamttorzahlen eintreten. Vielleicht liegt die erwartete Torzahl bei 2,8, aber die Simulation zeigt, dass in 58 Prozent der Durchläufe mehr als 2,5 Tore fallen und in 36 Prozent mehr als 3,5. Diese differenzierte Betrachtung ermöglicht präzisere Wettentscheidungen.
Handicap-Wetten profitieren ebenfalls von simulationsbasierten Analysen. Die Simulation liefert nicht nur Siegwahrscheinlichkeiten, sondern auch Verteilungen der Tordifferenz. Wenn das System zeigt, dass der Favorit in 62 Prozent der Fälle gewinnt, aber nur in 38 Prozent mit mindestens zwei Toren Unterschied, relativiert das die Attraktivität eines Minus-1,5-Handicaps erheblich. Die zusätzliche Bedingung reduziert die Gewinnwahrscheinlichkeit deutlich stärker, als viele Wetter erwarten.
Besonders spannend ist die Anwendung auf Live-Wetten. Moderne Systeme können Simulationen in Echtzeit aktualisieren, wenn sich der Spielstand ändert. Nach einem frühen Tor des Außenseiters verschieben sich die Wahrscheinlichkeiten dramatisch. Die ursprüngliche 30-prozentige Siegchance des Underdogs steigt auf 55 Prozent, während gleichzeitig die Quoten der Buchmacher reagieren. Wer schnell genug ist und die simulierten Wahrscheinlichkeiten kennt, kann von solchen Verschiebungen profitieren.
Die Simulation von Spielverläufen, nicht nur von Endergebnissen, ist der nächste Entwicklungsschritt. Dabei wird nicht nur berechnet, wie ein Spiel ausgeht, sondern wie es dorthin kommt. In welcher Minute fällt das erste Tor? Wie entwickelt sich der Expected-Goals-Verlauf über die 90 Minuten? Solche Simulationen sind deutlich rechenintensiver, liefern aber wertvollere Informationen für spezielle Wettmärkte wie Halbzeitergebnisse oder Torminuten.
Die Kombination mehrerer Simulationsquellen kann zusätzlichen Wert schaffen. Wenn verschiedene KI-Systeme zu ähnlichen Einschätzungen kommen, erhöht das die Konfidenz in die Prognose. Wenn sie stark abweichen, ist Vorsicht geboten, denn mindestens eines der Modelle muss falsch liegen. Diese Konsens-Strategie nutzen auch professionelle Wetter, um robustere Entscheidungen zu treffen.
Die Grenzen von Simulationen im Fußball
Bei aller Begeisterung für die Möglichkeiten der Monte-Carlo-Methode dürfen ihre Grenzen nicht vergessen werden. Fußball bleibt ein Spiel mit einem hohen Zufallsanteil, den auch die ausgefeilteste Simulation nicht eliminieren kann.
Unvorhersehbare Ereignisse sind der offensichtlichste Schwachpunkt. Ein Platzverweis in der ersten Halbzeit verändert das Spiel grundlegend. Verletzungen eines Schlüsselspielers während der Partie sind nicht vorhersagbar. Selbst Wetterbedingungen können sich schneller ändern als die Modelle aktualisiert werden. All diese Faktoren führen dazu, dass die Realität von den Simulationsergebnissen abweicht.

Psychologische Faktoren stellen eine weitere Herausforderung dar. Die Nervosität eines Spielers vor seinem 100. Länderspiel, die Motivationslage einer Mannschaft nach einem Trainerwechsel, die besondere Atmosphäre eines Derbys, all das lässt sich nicht in Zahlen fassen. Simulationen basieren auf historischen Daten, aber die Vergangenheit garantiert nicht die Zukunft. Ein Team kann aus unerklärlichen Gründen plötzlich über sich hinauswachsen oder zusammenbrechen.
Modellierungsgrenzen betreffen auch die mathematischen Annahmen selbst. Die meisten Simulationen gehen davon aus, dass Tore unabhängig voneinander fallen. In der Realität verändert ein Tor aber die Spielweise beider Teams. Manche Modelle versuchen, diese Abhängigkeiten abzubilden, aber perfekt gelingt das keinem. Ähnliches gilt für die Annahme konstanter Torwahrscheinlichkeiten über die Spielzeit, die der Realität mit ihren Schlussoffensiven und Ermüdungseffekten widerspricht.
Die Qualität der Eingabedaten begrenzt ebenfalls die Aussagekraft. Simulationen sind nur so gut wie die Statistiken, auf denen sie basieren. Bei Aufsteigern oder Teams mit vielen Neuzugängen fehlen relevante Daten aus der aktuellen Konstellation. Die Modelle müssen dann auf ältere oder weniger vergleichbare Daten zurückgreifen, was die Prognosequalität mindert. Der Algorithmus von BETSiE und ähnlichen Systemen erkennt zwar Datenmuster aus Jahrzehnten, aber die Frage bleibt, ob solch alte Werte für aktuelle Tipps relevant sind.
Schließlich besteht die Gefahr der Überinterpretation. Wenn eine Simulation 10.000 Mal läuft und in 4.800 Fällen ein Heimsieg herauskommt, sind das 48 Prozent. Aber diese 48 Prozent sind kein Naturgesetz, sondern das Ergebnis eines Modells mit all seinen Annahmen und Vereinfachungen. Die scheinbare Präzision der Zahlen kann trügerisch sein. Ein anderes Modell mit leicht veränderten Annahmen könnte 52 Prozent oder 44 Prozent liefern.
Die Buchmacher sind sich dieser Methoden bewusst und passen ihre Quoten entsprechend an. Umfassende KI-Prognosen in der Bundesliga sorgen dafür, dass eine große Masse an Sportwettern ähnliche Tipps ins Auge fasst, worauf die Buchmacher vorbereitet sind. Der Wettbewerbsvorteil von wirklich guten Tippern droht durch breit zugängliche KI-Daten ein gutes Stück eliminiert zu werden.
Die Frage der Datenverfügbarkeit spielt ebenfalls eine wichtige Rolle. Während für die Bundesliga umfangreiche Statistiken vorliegen, sieht es bei kleineren Ligen oder unteren Spielklassen anders aus. Je weniger Daten verfügbar sind, desto unsicherer werden die Simulationsergebnisse. Für Wetten auf exotische Ligen sollte man daher besonders vorsichtig sein und die Grenzen der Methodik im Hinterkopf behalten.
Auch die Rechenzeit kann bei komplexen Simulationen zum limitierenden Faktor werden. Während einfache Modelle innerhalb von Sekunden tausende Durchläufe schaffen, benötigen detaillierte Spielverlaufssimulationen deutlich mehr Zeit. Für Live-Wetten, bei denen schnelle Entscheidungen gefragt sind, kann das ein Problem darstellen. Die Entwicklung effizienterer Algorithmen ist daher ein aktives Forschungsfeld.
Praktisches Beispiel: Simulation eines Bundesliga-Spieltags
Zum Abschluss wollen wir die Theorie an einem konkreten Beispiel veranschaulichen. Wir simulieren gedanklich einen typischen Bundesliga-Spieltag mit neun Partien und zeigen, wie die Ergebnisse zu interpretieren sind.
Für jede Partie liegen Expected-Goals-Werte vor, die auf historischen Daten basieren. Das Topspiel Bayern München gegen Borussia Dortmund hat erwartete Werte von 2,3 für die Gastgeber und 1,5 für die Gäste. Ein Abstiegsduell zwischen zwei Kellertems zeigt Werte von 1,0 und 0,9. Diese Basiswerte gehen in die Simulation ein.
Bei jedem Durchlauf werden die tatsächlichen Tore durch Zufallsziehungen bestimmt, wobei die Poisson-Verteilung mit dem jeweiligen Expected-Goals-Wert als Parameter verwendet wird. Im ersten Durchlauf endet Bayern gegen Dortmund 3:1, im zweiten 2:2, im dritten 1:0. Nach 10.000 Durchläufen wird ausgezählt: Heimsieg in 5.600 Fällen (56 Prozent), Unentschieden in 2.100 Fällen (21 Prozent), Auswärtssieg in 2.300 Fällen (23 Prozent).
Die Gesamttorverteilung zeigt, dass in 34 Prozent der Simulationen weniger als 3 Tore fielen, in 66 Prozent mehr als 2,5 Tore. Der Median lag bei 3 Toren, der Mittelwert bei 3,1. Diese Informationen sind direkt für Über/Unter-Wetten nutzbar.
Für die exakten Ergebnisse liefert die Simulation ebenfalls Wahrscheinlichkeiten. Das häufigste Ergebnis war 2:1 mit 12 Prozent, gefolgt von 1:1 mit 11 Prozent und 2:0 mit 9 Prozent. Ein 0:0 kam in nur 4 Prozent der Simulationen vor, ein 5:3 in weniger als einem Prozent.
Der Vergleich mit den Buchmacher-Quoten zeigt, wo potenzielle Value Bets liegen. Wenn der Buchmacher für den Bayern-Sieg eine Quote von 1,65 anbietet (implizite Wahrscheinlichkeit 61 Prozent), aber die Simulation nur 56 Prozent ergibt, liegt kein Value vor, der Buchmacher sieht Bayern sogar stärker als die Simulation. Umgekehrt: Bietet ein Anbieter für Über 2,5 Tore eine Quote von 1,70 (59 Prozent), während die Simulation 66 Prozent zeigt, könnte hier ein interessanter Wettansatz liegen.
Über den gesamten Spieltag aggregiert die Simulation tausende Ergebnisse. Kombiniert man alle neun Partien, ergeben sich Wahrscheinlichkeiten für bestimmte Muster: In wie vielen Simulationen gab es mindestens sechs Heimsiege? Wie oft endeten drei oder mehr Spiele torlos? Solche Informationen können für Systemwetten oder spezielle Spieltagswetten wertvoll sein.
Die praktische Umsetzung erfordert Zugang zu geeigneten Daten und Rechenkapazität. Für den durchschnittlichen Sportwetter ist die eigene Simulation aller Spiele nicht realistisch. Hier kommen KI-Dienste ins Spiel, die diese Arbeit abnehmen und die Ergebnisse aufbereitet präsentieren. Die Wettbasis mit ihrem BETSiE-System ist ein Beispiel dafür, ebenso internationale Anbieter oder spezialisierte xG-Plattformen.

Das Verständnis der Simulationsmethodik hilft jedoch auch denjenigen, die selbst nicht simulieren. Wer weiß, wie die Zahlen zustande kommen, kann sie besser einordnen und kritischer hinterfragen. Nicht jede KI-Prognose ist gleich fundiert, und die Kenntnis der Methoden ermöglicht eine informierte Auswahl zwischen verschiedenen Anbietern.
Die saisonale Rendite von Systemen wie BETSiE zeigt, dass simulationsbasierte Tipps durchaus erfolgreich sein können. In der laufenden Bundesliga-Saison 2025/26 lag die Rendite zeitweise bei rund 13 Prozent, was über dem liegt, was mit Zufallstipps erreichbar wäre. Allerdings schwanken auch KI-Systeme, und einzelne Spieltage können negativ ausfallen. Die Kunst liegt darin, langfristig zu denken und sich nicht von kurzfristigen Rückschlägen entmutigen zu lassen.
Ein weiterer praktischer Aspekt ist die Frage der Wettmärkte. Simulationen liefern die besten Ergebnisse für Märkte, die direkt mit den simulierten Variablen zusammenhängen. Für Siegwetten, Über/Unter und Handicaps sind die Prognosen in der Regel zuverlässiger als für exotische Märkte wie den ersten Torschützen oder die Anzahl der Ecken. Wer simulationsbasiert wettet, sollte sich auf die Kernmärkte konzentrieren und spekulative Wetten meiden.
Die Entwicklung der Technologie schreitet weiter voran. Zukünftige Simulationssysteme werden noch mehr Faktoren berücksichtigen können, von Tracking-Daten einzelner Spieler bis zu Echtzeit-Wetterdaten. Die Grenze zwischen Simulation und Realität wird weiter verschwimmen, und die Prognosen werden noch genauer werden. Allerdings wird auch die Konkurrenz nicht schlafen, und die Buchmacher werden ihre Modelle ebenfalls verbessern.
Der Trend zu KI-basierten Wettentscheidungen ist unaufhaltsam. Wer heute noch rein intuitiv wettet, wird es gegen informierte Wetter und effiziente Buchmacher zunehmend schwer haben. Das bedeutet nicht, dass jeder zum Programmierer werden muss, aber ein grundlegendes Verständnis der Methodik ist unverzichtbar. Die in diesem Artikel vorgestellten Konzepte bieten einen Einstieg in diese Welt.
Letztlich ersetzen Simulationen weder Fachwissen noch Erfahrung. Sie sind ein Werkzeug unter vielen, das richtig eingesetzt zu besseren Entscheidungen führen kann. Die Kombination aus simulationsbasierten Wahrscheinlichkeiten, eigener Recherche und gesundem Menschenverstand bietet die besten Chancen auf langfristigen Wetterfolg. Wer allerdings erwartet, dass ein Computer ihm sichere Tipps liefert, wird enttäuscht werden. Denn auch die ausgefeilteste Simulation kann das Wesen des Fußballs nicht ändern: Er bleibt ein Spiel, bei dem manchmal der Bessere gewinnt, manchmal aber auch nicht.